计算机基础概念了解
进程 process
- 进程是操作系统进行资源分配和调度的基本单位
- 每个进程都有独立的内存空间,包括代码段、数据段、堆栈等
- 进程间通信需要通过 IPC (Inter-Process Communication) 机制
- 创建进程开销较大,切换成本高
- 一个程序运行时会创建一个或多个进程
线程 thread
- 线程是 CPU 调度的基本单位,是进程内的执行单元
- 同一进程内的多个线程共享进程的内存空间和资源
- 线程间通信比进程间通信更简单,直接通过共享内存
- 创建和切换线程的开销比进程小
- 线程安全性问题:多个线程同时访问共享资源可能引发竞态条件(race condition)
多进程 & 多线程
| 特性 | 多进程 | 多线程 |
|---|---|---|
| 资源开销 | 大(独立内存空间) | 小(共享内存) |
| 通信方式 | IPC(管道、消息队列等) | 共享内存 |
| 安全性 | 高(相互隔离) | 低(需要同步机制) |
| 扩展性 | 受限于机器CPU核心数 | 可创建大量线程 |
| 适用场景 | CPU密集型、高稳定性需求 | I/O密集型、需要快速响应 |
同步执行 sync
- 代码按顺序执行,前一个任务完成后再执行下一个任务
- 调用函数会阻塞当前执行流程,直到函数返回
- 逻辑简单直观,易于理解和调试
- 资源利用率低,特别是在I/O等待期间CPU空闲
- 示例:
result := readFile("data.txt")会等待文件读取完成再继续
异步执行 async
- 任务提交后立即返回,不等待任务完成
- 通过回调函数、Promise、Future等方式获取结果
- 提高系统吞吐量和响应速度
- 逻辑复杂,可能出现"回调地狱"
- 适合I/O密集型操作,如网络请求、文件读写
- 示例:
readFileAsync("data.txt", callback)提交后立即返回,文件读取完成后调用callback
阻塞 & 非阻塞
- 阻塞:调用函数时如果不能立即得到结果,调用者会挂起等待,不能执行其他操作
- 例如:同步网络请求、文件读写
- 非阻塞:调用函数时如果不能立即得到结果,函数会立即返回,通常返回一个状态或错误
- 例如:设置socket为非阻塞模式,调用recv如果无数据会立即返回错误
- 关键区别:调用后是否立即返回,不关注结果是否准备好
- 阻塞/非阻塞与同步/异步常被混淆,它们是从不同角度描述操作行为
协程 Coroutine
- 轻量级的用户态线程,由程序而非操作系统调度
- 优势:
- 创建开销小,可创建成千上万个协程
- 切换成本低,无需陷入内核态
- 内存占用小,通常KB级别
- 通过协作式调度,在特定点(yield)主动让出执行权
- 比线程更轻量,但需要程序员显式控制执行点
- 典型实现:Python的async/await, JavaScript的Promise/async-await, Lua的coroutine
Go 语言协程: Goroutine
- Go语言并发的基本单元,使用
go关键字创建 - 特点:
- 极轻量,初始栈大小仅2KB,可动态伸缩
- 由Go运行时(runtime)管理,对开发者透明
- 通过channel进行通信,遵循"CSP(Communicating Sequential Processes)"模型
- 自动调度,无需开发者手动控制切换点
- 与普通函数的区别:
- 普通函数:
doSomething() - Goroutine:
go doSomething()
- 普通函数:
- 注意:Goroutine没有返回值,通常通过channel传递结果
Go 语言并发模型: GMP
G (Goroutine):
- 表示单个Go协程
- 每个Goroutine有独立的栈、程序计数器和状态
- 轻量级,创建成本极低
M (Machine/OS Thread):
- 操作系统线程的抽象
- 负责执行Goroutine
- 数量通常与CPU核心数相关,可通过
GOMAXPROCS设置
P (Processor):
- 逻辑处理器,Goroutine调度的关键
- 拥有Goroutine队列,用于存储待执行的G
- 负责将G分配给M执行
- P的数量决定并行程度,通常等于CPU核心数
调度过程:
- 新创建的G放入P的本地队列
- M绑定P后,从P的队列中获取G执行
- 当G发生阻塞(如I/O)时,M会与P分离,P可与另一个空闲M绑定继续执行其他G
- 工作窃取(Work Stealing):当P的本地队列为空时,会从其他P的队列中"窃取"G来执行
优势:
- 高效利用多核CPU
- 减少线程切换开销
- 自动处理阻塞操作,不阻塞整个程序
Go 异步体验
package main
import (
"fmt"
"sync"
"time"
)
func watchTV() {
fmt.Println("看电视...")
}
func washClothes(wg *sync.WaitGroup) {
defer wg.Done() // 确保函数返回前调用Done,减少WaitGroup计数
fmt.Println("将衣服放到洗衣机中...")
fmt.Println("将洗衣液放到洗衣机中...")
fmt.Println("洗衣机开始洗衣服...")
time.Sleep(time.Second * 2) // 模拟耗时操作
fmt.Println("洗衣机洗衣服结束")
}
func main() {
// 同步等待组,用于等待所有goroutine完成
wg := sync.WaitGroup{}
wg.Add(1) // 增加计数,表示有一个goroutine需要等待
// go 关键字会将 washClothes() 放到 goroutine 本地队列中,
// 等待 processor 调度, 然后由 "Machine" 去执行它
go washClothes(&wg)
// 主goroutine继续执行watchTV,不等待washClothes完成
watchTV()
// 主goroutine等待,直到wg计数归零
wg.Wait()
fmt.Println("所有任务完成!")
}代码执行流程分析
- 主函数创建一个
sync.WaitGroup实例 - 调用
wg.Add(1)设置计数器为1 - 使用
go关键字启动washClothes协程 - 主协程继续执行
watchTV()函数 - 主协程调用
wg.Wait()等待计数器归零 washClothes协程执行完成后调用wg.Done()使计数器减1- 主协程继续执行后续代码

关键点
- 并发执行:洗衣服和看电视同时进行,提高效率
- 同步机制:WaitGroup确保主函数等待所有协程完成后再退出
- 资源管理:通过
defer wg.Done()确保即使函数发生panic也会正确减小计数器 - 调度过程:Go运行时自动将Goroutine分配给系统线程执行
运行结果
看电视... // 这个步骤也可能在后面, 主要取决与调度器
将衣服放到洗衣机中...
将洗衣液放到洗衣机中...
洗衣机开始洗衣服...
洗衣机洗衣服结束
所有任务完成!WaitGroup 等待组原理分析
我这里是为了理解代码执行流程做的笔记, 实际处理不会这么简单粗暴
package main
import (
"fmt"
"time"
)
type MyWaitGroup struct {
unfinishAsyncTasks int
}
互斥锁
异步任务数据竞争现象
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
// 启动10个goroutine
var counter int
for range 10 {
wg.Go(func() {
for range 1000 {
counter += 1 // 这里存在数据竞争,
// 可能第一个 goroutine 的加法还没计算完,
// 其他的 goroutine 就开始执行了, 导致获取的值不对
}
})
//// 上面代码与这个代码等价, 具体查看 wg.Go 方法源码实现
// wg.Add(1)
// go func() {
// defer wg.Done()
// for range 1000 {
// counter++ // 这里存在数据竞争
// }
// }()
}
wg.Wait()
fmt.Println("最终计数器值:", counter) // 每次输出可能不一致
}互斥锁解决数据竞争
这也是为需要互斥锁的原因
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
var lk sync.Mutex
// 启动10个goroutine
var counter int
for range 10 {
wg.Go(func() {
for range 1000 {
lk.Lock() // 当锁定 counter 变量的时候, 其他 goroutine 就必须等待解锁才能访问
counter += 1 // 这里存在数据竞争, 那么就锁定它, 等操作完成之后才允许其他 goroutine 操作
lk.Unlock()
}
})
}
wg.Wait()
fmt.Println("最终计数器值:", counter) // 每次输出 10000
}原子操作解决数据竞争
可以将原子操作看做一个 数据库事物, 事物操作数据期间, 会锁定数据表数据, 等待事物提交/回滚后才会解锁
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var wg sync.WaitGroup
var counter int32 = 0
// 启动10个goroutine
for range 10 {
wg.Go(func() {
for range 1000 {
// lk.Lock()
// counter += 1
// lk.Unlock()
// 这一行代码,等价于上面3行代码
atomic.AddInt32(&counter, 1)
}
})
}
wg.Wait()
fmt.Println("最终计数器值:", counter) // 每次输出 10000
}为什么需要互斥锁?
本质是因为多个线程共享了同一个内存, 导致的数据互相竞争, 为了防止这种竞争, 就需要加锁 但是加锁的这种操作, 并不符合 Go 语言的并发哲学
Go语言的并发哲学
不要通过共享内存来通信, 而是应该通过通信来共享内存
那么不使用互斥锁, 应该如何解决并发的数据竞争问题呢? 答案是使用 channel
读写锁 RWMutex
- 读锁: 只能读取不能写入
lk.RLock()lk.RUnlock() - 写锁: 同一时刻只能有一个写入, 不允许读取
lk.Lock()lk.Unlock()
package main
import (
"fmt"
"sync"
"time"
)
var (
counter int
rwMutex sync.RWMutex // 声明一个读写锁
)
// 读操作函数
func reader(id int, wg *sync.WaitGroup) {
defer wg.Done()
rwMutex.RLock() // 获取读锁
value := counter
time.Sleep(time.Millisecond) // 模拟读取耗时
fmt.Printf("读取器 %d 读取到值: %d\n", id, value)
rwMutex.RUnlock() // 释放读锁
}
// 写操作函数
func writer(id int, wg *sync.WaitGroup) {
defer wg.Done()
rwMutex.Lock() // 获取写锁(独占)
old := counter
counter = old + 1
time.Sleep(time.Second) // 模拟写入耗时
fmt.Printf("写入器 %d 将值修改为: %d\n", id, counter)
rwMutex.Unlock() // 释放写锁
}
func main() {
var wg sync.WaitGroup
// 启动 5 个读协程
for i := range 5 {
wg.Add(1)
go reader(i, &wg)
}
// 启动 2 个写协程
for i := range 3 {
wg.Add(1)
go writer(i, &wg)
}
wg.Wait()
}通道 channel
中文翻译: 通道 管道
体验通道
package main
import "fmt"
func main() {
// 1.创建一个通道
// int 表示这个管道只允许发送 int 类型的数据
c := make(chan int)
// 2.将数据放到通道中
go func() {
c <- 1
c <- 2
c <- 3
}()
// 3.从通道中获取数据 FIFO
v1 := <-c
v2 := <-c
v3 := <-c
fmt.Println("v1:", v1) // 1
fmt.Println("v2:", v2) // 2
fmt.Println("v3:", v3) // 3
// 4.关闭通道
close(c)
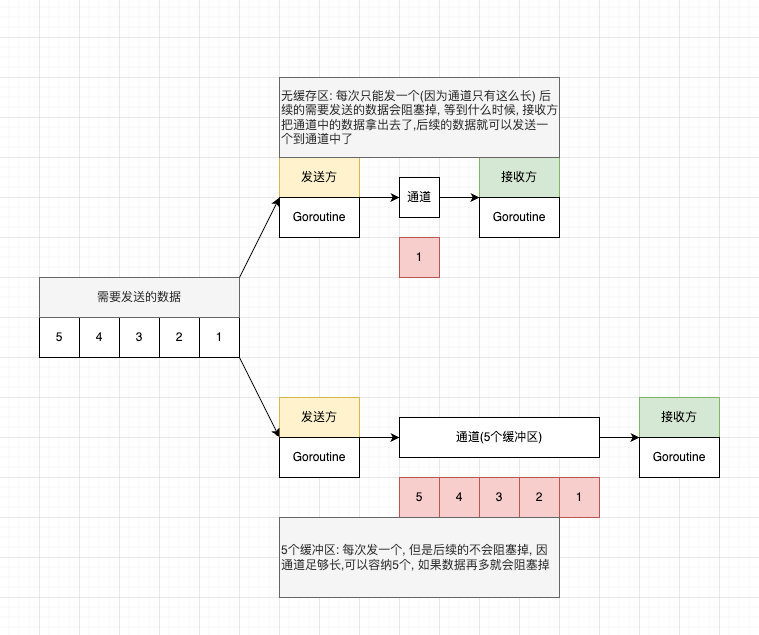
}通道缓冲
package main
import (
"fmt"
"time"
)
func main() {
// 创建一个通道
// int 表示这个管道只允许发送 int 类型的数据
c := make(chan int)
s := []int{1, 2, 3, 4, 5}
// 将数据放到通道中
go func() {
defer close(c)
for _, v := range s {
fmt.Println("发送", v)
c <- v
time.Sleep(time.Second)
}
}()
// 3 秒之后才开始从通道中获取数据
time.Sleep(3 * time.Second)
for i := range c {
fmt.Println("接收", i)
}
}package main
import (
"fmt"
"time"
)
func main() {
// 创建一个通道, 并且有5个缓冲区位置
s := []int{1, 2, 3, 4, 5}
c := make(chan int, len(s))
// 将数据放到通道中
go func() {
defer close(c)
for _, v := range s {
fmt.Println("发送", v)
c <- v // 这里不会再阻塞发送
time.Sleep(time.Second)
}
}()
// 10 秒之后才开始从通道中获取数据
time.Sleep(10 * time.Second)
fmt.Println("开始获取数据")
for i := range c {
fmt.Println("接收", i)
}
}
通道方向
也叫单向通道(只能发送或只能接收)
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.WaitGroup{}
wg.Add(2)
c := make(chan int)
// 这个通道只能 发送数据, 不能接收数据
go func(c chan<- int) {
defer wg.Done()
fmt.Println("send data:", 1)
c <- 1
// v := <- c
// invalid operation: cannot receive from send-only channel chan<- int c (variable of type chan<- int)
}(c)
// 这个通道 只能接收数据, 不能发送数据
go func(c <-chan int) {
defer wg.Done()
v := <-c
fmt.Println("receive data:", v)
// c <- 2
// invalid operation: cannot send to receive-only channel <-chan int c (variable of type <-chan int)
}(c)
wg.Wait()
close(c)
}通道导致死锁
什么是死锁
一直阻塞导致程序无法正常往下执行或者退出的情况 所以, 开发时应该避免这些情况, 以保证代码的健壮性 以下代码常见会导致死锁的情况
package main
import "fmt"
/*
情况1: 这个代码是可以通过编译的
一个通道(不管是否有缓冲区),没有发送方Goroutine(往通道中放数据),
直接去接收数据就会导致死锁,其中没有数据就会一直阻塞着等待通道中的数据
*/
func main() {
c := make(chan int)
v := <-c
fmt.Println("v:", v)
}package main
/*
情况2: 这个代码是可以通过编译的,但是运行时会报致命错误
无缓冲区通道,有发送方Goroutine,但是没有接收方,就会导致死锁
因为没有其他Goroutine去接收数据, 数据就会一直占用着通道, 导致死锁
如果有缓冲区, 且数据不超过缓冲区大小, 就不会死锁, 因为会将数据放到缓冲区中
*/
func main() {
c := make(chan int)
c <- 1
}package main
/*
情况3:
有缓冲区通道,只有发送放Goroutine,没有接收方,一直往通道中发送数据, 当数据
超出最大缓冲区的时候,就会导致死锁
*/
func main() {
c := make(chan int, 3)
// 前面3个数据不会报错,因为有缓冲区
c <- 1
c <- 2
c <- 3
c <- 4 // 这一行会导致报错
}package main
import "fmt"
/*
情况4:
通道未初始化,就直接用通道去发送/接收数据,都会导致死锁
此时的变量 c 还是个 nil, 不可能可以使用 <- 操作符
*/
func main() {
var c chan int
// c <- 1
v := <-c
fmt.Println("v:", v)
}package main
import (
"fmt"
"sync"
)
/*
情况5:
循环的接收数据,发送方没有关闭通道,导致接收方一直在从通道中获取数据,
如果数据获取完了(没有数据了), 此时通道还没有关闭再次获取数据就会导致死锁
*/
func main() {
wg := sync.WaitGroup{}
wg.Add(2)
c := make(chan int)
go func(c chan<- int) {
defer wg.Done()
defer close(c) // 如果没有这一行代码主动关闭通道
// 接收的时候就会一直从通道中读取数据
// 数据已经被读取完了, 还从通道中读数据就会一直阻塞住, 导致死锁
for i := range 5 {
fmt.Println("send", i)
c <- i
}
}(c)
go func(c <-chan int) {
defer wg.Done()
for {
v, ok := <-c
if !ok {
break
}
fmt.Println("recv", v)
}
}(c)
wg.Wait()
}通道同步
由于从通道读取数据的操作是阻塞的, 所以我们可以使用通道来同步 Go 协程间的执行状态
package main
import (
"fmt"
"time"
)
func asyncTask(ch chan<- bool) {
fmt.Println("3.异步任务开始")
time.Sleep(time.Second * 3)
fmt.Println("4.异步任务结束")
ch <- true
}
func main() {
ch := make(chan bool)
fmt.Println("1.这是主线程")
go asyncTask(ch)
fmt.Println("2.主线程后续代码")
isDone := <-ch // 这句代码会阻塞住主线程
if isDone {
fmt.Println("5.任务执行完成")
}
// 等到 asyncTask 写入数据后, 这个阻塞才会打开
// 这个输出语句才会执行
fmt.Println("6.主线程执行完成了")
// 整体输出如下:
// 1.这是主线程
// 2.主线程后续代码
// 3.异步任务开始
// 4.异步任务结束
// 5.任务执行完成
// 6.主线程执行完成了
}通道选择器
在 Go 中, select 是一种管道多路复用的控制结构
什么是多路复用?
简单的概括就是: 在某一时刻, 同时监测多个元素是否可用, 被监测的可以是网络请求, 文件 IO 等
Go 中的 select 监测的元素就是管道, 也就是说: select 可以同时检测多个管道是否有可读的数据
package main
import (
"fmt"
"time"
)
func main() {
chan1 := make(chan string)
chan2 := make(chan string)
go func(c chan<- string) {
time.Sleep(time.Second * 1)
fmt.Println("G1 send")
c <- "one"
}(chan1)
go func(c chan<- string) {
time.Sleep(time.Second * 2)
fmt.Println("G2 send")
c <- "two"
}(chan2)
for range 4 {
fmt.Println("--- start select ---")
// select 与 switch 类似, 一次只会命中一个 case, 但与 switch 不同的是:
// 1. select 语句只能用于通道操作, 且每个 case 都必须是读取通道数据
// 2. select 语句执行一次只会命中一个case, 需要监听3个通道, 所以要至少要 select
// 3次, 才能分别获取3个通道的值
select {
case msg1 := <-chan1:
// 程序执行到这里: 这个 <-chan1 在还没有读取到数据之前
// 会阻塞掉 for 循环继续运行, 当读取到数据后, 就会命中这个 case
// 然后执行完 fmt.Println 后, 就会退出这个 select
fmt.Println("chan1 recv:", msg1)
case msg2 := <-chan2:
// 程序执行到这里: 这个 <-chan2 与 chan1 同理,
// 没有获取到数据之前就阻塞 for, 获取到数据就会命中当前 case
// 然后执行输出语句, 继而退出 select
fmt.Println("chan2 recv:", msg2)
case <-time.After(time.Second * 5):
// 程序执行到这里: 就会执行 time.After 方法
// 这个 time.After 方法会返回一个通道(如: timeAfterChan)
// 且这个通道只有在 n 秒之后才会发送一个值(也就是说读取到值时就已经过去n秒了)
// 而 <-timeAfterChan 读取通道数据会阻塞for循环,
// 只有读取到值后才会命中这个 case, 然后在执行 fmt.Println 后
// 就会退出这个 select
fmt.Println("timeout")
}
}
}package main
import (
"fmt"
"time"
)
func main() {
taskChan := make(chan string)
timeoutChan := time.After(time.Second * 5)
go func(c chan<- string) {
time.Sleep(time.Second * 10)
fmt.Println("taskChan send")
c <- "one"
}(taskChan)
// 只执行一次 select, 那么两个 case 只会命中其中一个然后退出
select {
case msg1 := <-taskChan:
// 如果命中了这个 case, 说明 taskChan 先发送了数据
fmt.Println("chan1 recv:", msg1)
case <-timeoutChan:
// 如果命中了这个 case, 说明 timeoutChan 先发送了数据
// 那就说明已经过去 5 秒钟了, 都没有从 taskChan 读取到数据
// 所以知道任务已经过超时了
fmt.Println("timeout")
}
}package main
import "fmt"
func main() {
chan1 := make(chan int, 1)
chan1 <- 1
fmt.Println("--- select start1 ---")
select {
case num := <-chan1: // 命中, 因为 chan1 中有数据
fmt.Println("从chan1通道中读取到数据:", num)
default:
fmt.Println("未从chan1通道中读取到的数据")
}
chan2 := make(chan int, 1)
go func() {
fmt.Println("发送数据到chan2")
chan2 <- 2
}()
fmt.Println("--- select start2 ---")
select {
case num := <-chan2:
fmt.Println("从 chan2 通道中读取到数据:", num)
default:
// 命中, 因为执行 select 的时候, chan2 中还没有数据
// 为什么没有数据? 因为 goroutine 是异步执行的,
// 所以此时还没发送数据到管道中
// 所以会命中到 default 语句, 而不会阻塞
fmt.Println("未从 chan2 通道中读取到的数据")
}
loop: // 定义一个 loop 代码块
for { // 一直死循环, 直到主动退出 loop 代码块
fmt.Println("--- select start3 ---")
select {
case num := <-chan2:
fmt.Println("从 chan2 通道中读取到数据:", num)
break loop // 退出 loop 代码块
default:
// 所谓的异步通道就是: 因为有 select 有 default 语句
// 导致从通道中接收数据不会阻塞, 因为 select 每次判断
// 都会命中到 default, 然后退出 select, 所以不会阻塞
fmt.Println("未从 chan2 通道中读取到的数据")
}
}
}练习: 控制并发数量
package main
import (
"fmt"
"time"
)
func main() {
jobCount := 10 // 未完成任务数
jobsChan := make(chan int) // 发送任务通道
doneChan := make(chan bool) // 是否完成通道
go func() {
for { // 注意需要不停的接收, 否则只会接收一次
jobID, ok := <-jobsChan
if ok {
// 读一个就停1s模拟任务执行所需时间
fmt.Println("recv:", jobID)
time.Sleep(time.Second)
} else {
fmt.Println("received all jobs")
doneChan <- true
return // 退出循环, 结束函数
}
}
}()
for jobID := range jobCount {
jobsChan <- jobID // 没有缓冲区所以每次只能发送一个任务, 后续会阻塞住
fmt.Println("send:", jobID)
}
close(jobsChan) // 当循环走完, 那么任务也执行完了
fmt.Println("sent all jobs")
// 等待所有任务完成, 读取数据会阻塞主进程不能结束
<-doneChan
}package main
import (
"fmt"
"time"
)
func main() {
workers := 5 // 每次执行5个任务
jobCount := 10 // 未完成任务数
jobsChan := make(chan int) // 发送任务通道
doneChan := make(chan bool) // 是否全部完成通道
// 开启 5 个 goroutine, 一直接收通道发送的任务
for range workers {
go func() {
// 通道是可以直接遍历的, 有数据就会被接收
for jobID := range jobsChan {
// 接收一个就停1s模拟任务执行所需时间
fmt.Println("recv:", jobID)
time.Sleep(time.Second) // execJob(jobID) 模拟执行任务
}
// 遍历完了说明: 没有数据可以接收了
fmt.Println("computed all jobs")
doneChan <- true
}()
}
for jobID := range jobCount {
jobsChan <- jobID
// 一次发一个任务到通道, 但是有5个goroutine在接收
// 也就是说发一个就被很快被接收,直到发满5个
// 后续的才会阻塞
fmt.Println("send: ", jobID)
}
close(jobsChan) // 任务发送完了, 关闭通道让通道读不到数据
fmt.Println("sent all jobs")
<-doneChan
}上下文 Context
文档: https://pkg.go.dev/context
Context 介绍
Context译为上下文, 是Go提供的一种并发控制的解决方案, 相比于管道和WaitGroup, 它可以更好的控制子孙协程以及层级更深的协程, Context本身是一个接口, 只要实现了该接口都 可以称之为上下文例如著名Web框架Gin中的 gin.Context, context标准库也提供了几个实现,分别是:
- emptyCtx:
background方法和todo方法 的返回值就是emptyCtx - cancelCtx:
withCancel方法的返回值就是cancelCtx - timerCtx:
withDeadline方法 和withTimeout方法的返回值就是timerCtx - valueCtx:
withValue方法的返回值就是valueCtx, 用来储存/取值
Context 是什么?
Context 是一个接口
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key any) any
}Context 可以用来做什么
Context 的主要用途是当一个请求被取消或超时时, 所有由该请求派生的 Goroutine 都能快速清理并退出, 释放资源
核心原则:
- 不要将
Context存入结构体,而应该显式地将Context作为第一个参数传递给需要它的函数, 通常命名为ctx Context是并发安全的,可以被任意多个 Goroutine 同时使用Done()方法返回一个chan,当该chan被关闭时,表示此Context被取消或超时Err()方法返回取消的原因(例如context.Canceled或context.DeadlineExceeded) 它是一个errors.New("message")
Context 快速入门
- context.Background()
- context.Todo()
Go 提供了两个内置的根 Context,只能通过它们派生出子 Context
context.Background()
- 返回一个空的 Context, 它通常用于 main 函数、初始化过程以及测试中作为请求的起点
- 这是一个永远不会被取消的 Context,没有截止时间,也没有值
context.TODO()
- 当不清楚该使用哪个 Context,或者函数尚未扩展支持 Context 参数时使用
- 它是一个占位符,提醒开发者将来应该传入合适的 Context
withCancel
package main
import (
"context"
"fmt"
"time"
)
func worker(ctx context.Context, workerID int) {
for {
select {
case <-ctx.Done():
// 当 ctx.Done() 通道关闭时, 进入此分支
fmt.Printf("worker-%v stopped %v \n", workerID, ctx.Err())
return
default:
fmt.Printf("worker-%v working...\n", workerID)
time.Sleep(time.Second)
}
}
}
func main() {
// 1. 创建根 Context
ctx := context.Background()
// 2. 派生一个可取消的 Context
ctx, cancel := context.WithCancel(ctx)
// 3. 启动多个工作 Goroutine
for i := range 5 {
go worker(ctx, i)
}
// 4. 主程序运行 3 秒后,调用 cancel
time.Sleep(3 * time.Second)
fmt.Println("Main: cancelling context...")
cancel() // 像 ctx.Done() 这个通道发送消息, <-ctx.Done() 可以读取到
// 等待所有 worker 结束
time.Sleep(time.Second)
}withDeadline
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx := context.Background()
// 设置截止时间为 5 秒后
deadline := time.Now().Add(5 * time.Second)
ctx, cancel := context.WithDeadline(ctx, deadline)
defer cancel()
fmt.Println("Deadline set for:", deadline.Format("15:04:05"))
select {
case <-time.After(10 * time.Second):
fmt.Println("Task finished")
case <-ctx.Done():
// 因为 ctx 的截止时间(5秒)先到达,所以会先触发
// 错误信息: context deadline exceeded
fmt.Println("Context cancelled due to deadline:", ctx.Err())
}
}withTimeout
package main
import (
"context"
"fmt"
"time"
)
func slowyOperation(ctx context.Context) error {
// 模拟一个耗时操作,比如网络请求
select {
case <-time.After(3 * time.Second):
fmt.Println("Operation completed successfully")
return nil
case <-ctx.Done():
// 如果在 3 秒内 Context 被取消(超时), 则进入此分支
fmt.Println("Operation timed out:", ctx.Err())
return ctx.Err()
}
}
func main() {
// 设置一个 2 秒的超时
timeout := time.Second * 5
// timeout := time.Second * 2
ctx, cancel := context.WithTimeout(context.Background(), timeout)
defer cancel()
err := slowyOperation(ctx)
if err != nil {
// 处理超时错误
fmt.Println("Error:", err)
}
}WithValue
在不同的 goroutine 之间存值/取值
package main
import (
"context"
"fmt"
)
// 0. 定义一个类型, 专门用于传值(直接使用 string 类型会报警告)
type userIDKeyType string
const userIDKey userIDKeyType = "user_id"
// 1.模拟中间件, 向 Context 中添加用户 ID
func mockLogin(ctx context.Context, id string) context.Context {
return context.WithValue(ctx, userIDKey, id)
}
// 2.业务逻辑函数, 从 Context 中获取用户 ID
func userProfile(ctx context.Context) {
// 从 Context 中获取值, 注意:必须进行类型断言
userID, ok := ctx.Value(userIDKey).(string)
if ok {
fmt.Printf("userId: %v \n", userID)
} else {
fmt.Println("userID not found in context")
}
}
func main() {
ctx := context.Background()
// 模拟用户登录,获取 ID 并存入 Context
ctx = mockLogin(ctx, "1001")
userProfile(ctx)
}总结
| 函数/方法 | 用途 | 触发条件 |
|---|---|---|
Background / TODO | 根 Context | 手动设置 |
WithCancel | 手动取消 | 调用 cancel() |
WithDeadline | 绝对时间取消 | 到达指定时间点 |
WithTimeout | 相对时间超时 | 经过指定时长 |
WithValue | 传递数据 | 无(仅存储数据) |